
Apache Kafka is a buzz word these days. Originally developed by LinkedIn in 2011 the project has been donated to Apache, many companies have successfully adopted the technology. But what is this buzz word all about, what does it do? Why does everyone these days talk about it? What was the existing solution it replaced? And does it really justifies the change?
In this post, we'll try to answer all these questions. We'll start with the basic introduction of Kafka, then will see its use-cases, after that will dive into some demonstration and coding of how you can get started with Kafka using Java.
What is Kafka?
Kafka is distributed publish-subscriber message delivery system that is designed to be fast, durable, scalable in very simple terms. But as you go deeper into the design and technicality of the architecture it's a large system. We are not going to discuss the entire design in this post however, you can get more insight about the design of Kafka by reading Kafka Documentation.
Kafka has following 4 core API's::
Producer API - Allows to push messages to one or more topics. Consumer API - Allows to consume messages from one or more topics. Streams API - Allows to consume input stream from one or more topics producing an output stream to one or more topics, effectively converting input streams to output streams. Connector API - Allows building a reusable producers and consumers that connects to Kafka topics to existing applications or data system.
Apache Kafka Architecture
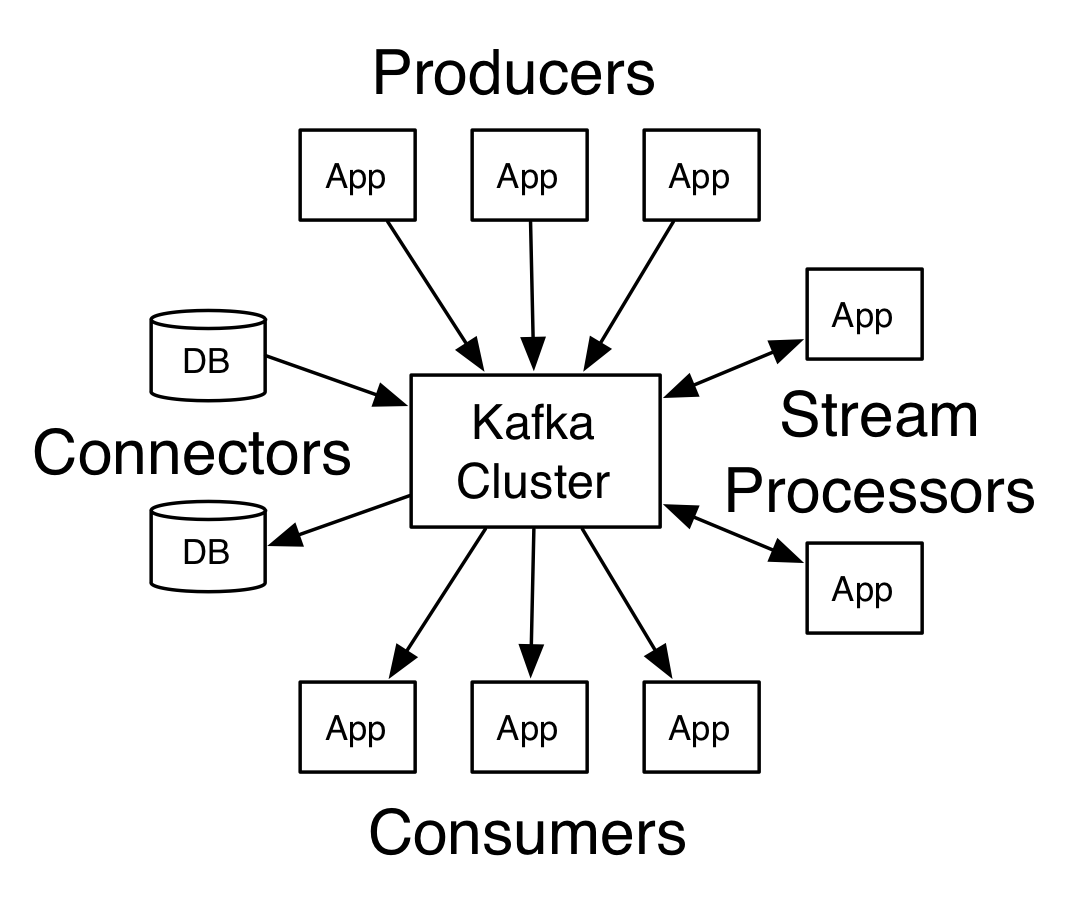
Like other publish-subscribe messaging systems, Kafka maintains feeds of messages in topics. One or more Producers writes to the topic whereas consumers consume from the topic. As Kafka is distributed platform topics are partitioned and replicated across multiple nodes.
Message to the topics are simple byte array and developers can store messages in any form of String, Json etc. Each message is associated with a key and producer guarantees that messages with the same key will arrive at the same partition. Consumers can be organized into consumer groups in which case Kafka makes sure that each consumer within the consumer group will receive exactly one message to the partitioned within the topic it subscribes too i.e each consumer in a consumer group reads from a unique partitioned of topic to which no other consumer within the consumer group will have access, thus all the messages that arrive at the unique partitioned which is identified by a unique key will be delivered to the same consumer always.
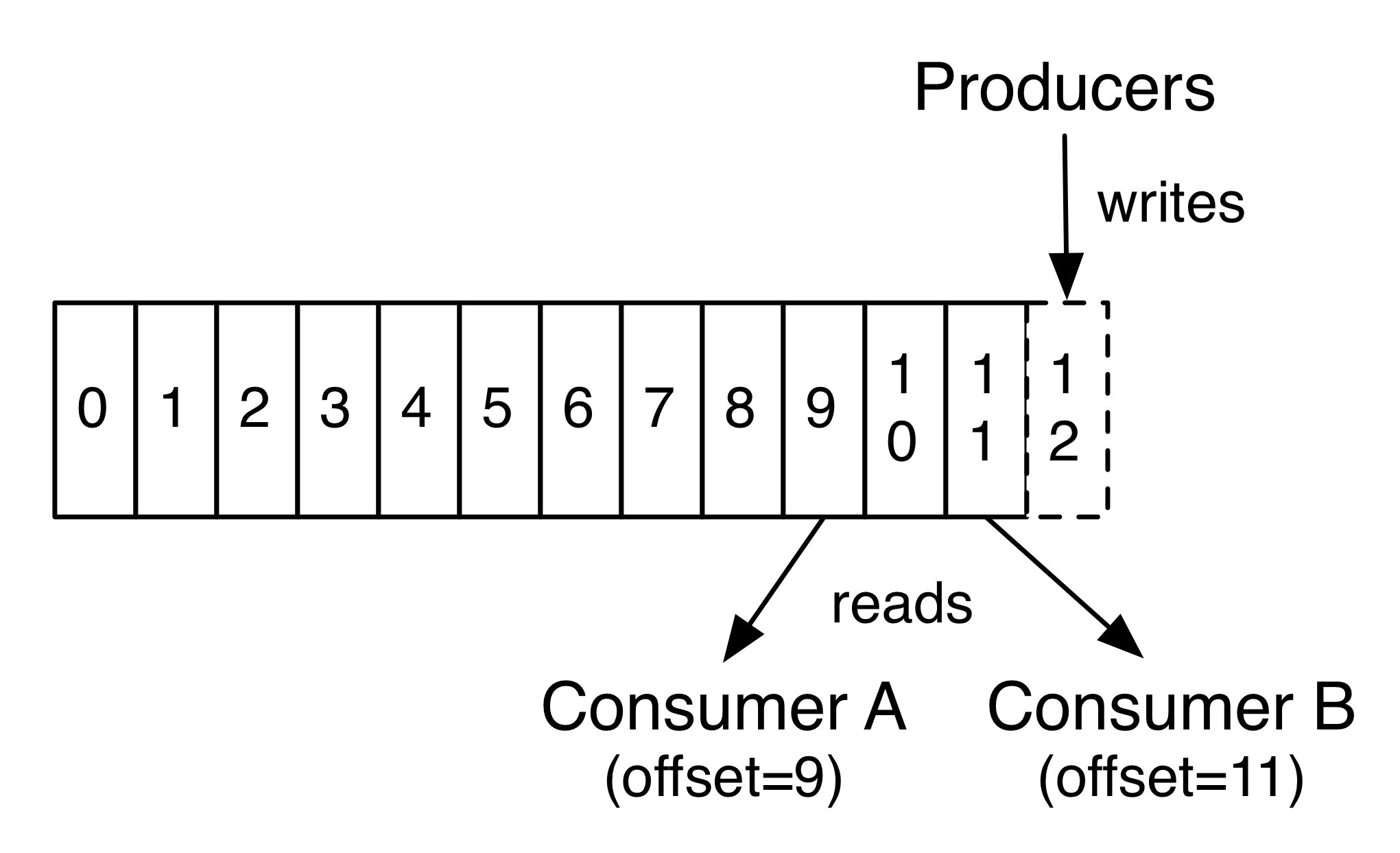
Kafka treats each topic as a log(ordered sequence of messages) like a pipeline where messages come from one end and are consumed from another end, each message in a partitioned is assigned a unique offset. Kafka does not maintain any detail of which message is read by each consumer and only retains unread messages rather, Kafka retains messages for a certain amount of time and consumer are responsible to track their location in each log. Kafka can maintain a large amount of data without any issue.
Use Cases::
Website activity tracking:: Web Apps can send events to Kafka such as page clicks, page search for real-time processing and analytics.
Log aggregation:: Logs can be aggregated from multiple servers which can be analyzed in real time or will be available to tools like Hadoop or Apache Solr.
Stream Processing:: Framework like Apache Spark can stream data from a topic, process it and writes the processed data to the new topic. This processed data then can be made available to the customer or another application for further processing.
Operational Metrix:: Alert monitoring and notification can be done by analysing the metadata or logs. Other way application can send stats or counts to the topic which will be then compared and visualized as a dashboard.
Others system may serve the purpose but none of them does all. Like ActiveMQ and RabbitMQ are a very popular messaging system. Google PubSub is also one of the great messaging platforms but does not provide on premises solutions. I have also heard about the performance and throughput of Kafka as oppose to others.
Now, let's get into the coding stuff will see how you can install Kafka on your local machine and perform operations like creating, deleting, listing topics, sending and receiving messages to the topic.
Installing Kafka
For this I am using a windows machine so I will be explaining installing Kafka on windows, however, Unix and Mac's setup is also same. Kafka binaries are packaged into zip folder which needs to be extracted. Download the binaries extract it somewhere on your machine. Execute the following commands to start Kafka on your local machine. For windows machine the bat files are located inside bin\windows.
> bin/zookeeper-server-start.sh config/zookeeper.properties
[2017-09-03 19:00:38,859] INFO Reading configuration from: ..\config\zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)...
...You need to first start the Zookeeper instance. There are scripts packaged into the Kafka binaries the above command starts the zookeeper instance.
> bin/kafka-server-start.sh config/server.properties
[2017-09-03 19:03:59,553] INFO starting (kafka.server.KafkaServer)
[2017-09-03 19:03:59,590] INFO Connecting to zookeeper on localhost:2181 (kafka.server.KafkaServer)
...The above command will start Kafka server and the the broker address will be localhost:9092.
Creating a Topic
Creating a topic using cmd is fairly simple. Run the following command to create a "test" topic.
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTo list all the topics::
> bin/kafka-topics.sh --list --zookeeper localhost:2181 testTo delete a Topic::
> bin/kafka-topics.sh --zookeeper localhost:2181 --delete testEvery command given above will work with your console. Let's move to the programming part and see how to use API in java. Will try to do the above operations using Kafka Admin Client API and then will write a simple producer and consumer that sends and messages to the Topic we create.
Project Setup
I will be using maven for the project and the Maven configuration for the project is as follows::
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.kafka.samples</groupId>
<artifactId>kafka-learning</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version><4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>The Kryo library in our pom.xml is used to write custom Serializer and Deserializer for Kafka which is explained furture in the post.
Creating a Topic::
You will require properties like bootstrap.server and client.id to configure the admin client. You can read about all the configuration options in Kafka Documentation but for now, as we are not dealing with configurations like secure SSL, bootstrap.server will be enough to connect to the Kafka Server.
public class CreateTopic {
public static void main(String[] args) throws IOException {
Properties properties = ConfigUtils.getConfiguration("admin-config");
AdminClient adminClient = AdminClient.create(properties);
CreateTopicsResult result = adminClient.createTopics(Arrays.asList(new NewTopic("test1", 1, (short)1)));
System.out.println("Topic Created: ");
}
}The arguments to NewTopic is the new topic name, number of partitioned and replication factor.
Listing All Topics::
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.ListTopicsResult;
public class ListTopics {
public static void main(String[] args) throws IOException, InterruptedException, ExecutionException {
Properties prop = ConfigUtils.getConfiguration("admin-config");
AdminClient admin = AdminClient.create(prop);
ListTopicsResult topics = admin.listTopics();
Set<String> topicNames = topics.names().get();
for(String topic: topicNames) {
System.out.println(topic);
}
}
}Delete Topic::
public class DeleteTopic {
public static void main(String[] args) throws IOException, InterruptedException, ExecutionException {
Properties prop = ConfigUtils.getConfiguration("admin-config");
ZkClient zkClient = ZkUtils.createZkClient(prop.getProperty("bootstrap.server"), 100, 10000);
zkClient.deleteRecursive(ZkUtils.getTopicPath("test2"));
}
}Producer To Send Messages::
Here is our simple Kafka producer that sends Hello World message to test topic.
package com.kafka.sample;
import java.io.IOException;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class SimpleProducer {
private Producer<Long, Employee> producer;
long count = 0;
public SimpleProducer() throws IOException {
if (producer == null) {
createProducer();
}
}
public SimpleProducer(Producer<Long, Employee> producer) {
this.producer = producer;
}
private void createProducer() throws IOException {
Properties configuration = ConfigUtils.getConfiguration("producer-config");
producer = new KafkaProducer<>(configuration);
}
public void sendMessage(String topic, Employee message) throws IOException {
producer.send(new ProducerRecord<Long, Employee>(topic, count++, message));
producer.flush();
producer.close();
System.out.println("Done");
}
public void close() {
producer.close();
}
public static void main(String[] args) throws IOException {
SimpleProducer producer = new SimpleProducer();
Employee emp = new Employee();
emp.setEmpId(101);
emp.setFirstName("Ninad");
emp.setLastName("Ingole");
emp.setJoiningDate(new Date());
producer.sendMessage("test", emp);
producer.close();
}
}Configuration is fairly simple for this example::
bootstrap.servers=localhost:9092
key.serializer=org.apache.kafka.common.serialization.LongSerializer
value.serializer=org.apache.kafka.common.serialization.StringSerializer
client.id=kafka-client-1bootstrap.servers is a list of comma separated values of all the Kafka servers, you will have three or more depending on your cluster configurations. The key.serializer and value.serializer is required for serializing messages at producer end. Few Serializer and Deserializer are available for wrapper types in Kafka. However, if you are sending your own message type you need to implement org.apache.kafka.common.serialization.Serializer and provide your own implementation. client.id is needed to uniquely identify the producer in Kafka and Kafka logs.
Consumer to Pull the messages::
package com.kafka.sample;
import java.io.IOException;
import java.util.Collections;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class SimpleConsumer {
public static void main(String[] args) throws IOException {
SimpleConsumer consumer = new SimpleConsumer();
consumer.recieveAndPrintMessage("test");
}
public void recieveAndPrintMessage(String topic) throws IOException {
Properties prop = ConfigUtils.getConfiguration("consumer-config");
KafkaConsumer<Long, String> consumer = new KafkaConsumer<>(prop);
consumer.subscribe(Collections.singletonList(topic));
ConsumerRecords<Long, String> consumerRecords = consumer.poll(1000L);
for (ConsumerRecord<Long, String> record : consumerRecords) {
String message = record.value();
System.out.println(message);
}
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
consumer.commitAsync();
consumer.close();
}
}The example given above will create a KafkaConsumer using consumer properties and will subscribe to the test topic. It will poll the topic for 1sec and return all the messages in the topic as ConsumerRecords which is a collection of ConsumerRecord i.e a message on the topic. The type is same as that of the producer <Long, String>. You can retrieve the value of a ConsumerRecord by calling value() method on it. Other information can also be inferred from ConsumerRecord like checksum, headers, topic, key etc.
In the example, We just poll the topic once for 1sec and it will get some messages but not all. However, in a real scenario, you will poll the topic multiple times in a loop. Once the messages are read by poll method we need to commit the offset for the last returned poll offset, there are two ways to commit one is commitSync which will block until the commit succeeds or some error occurs and the other is commitAsync which will not block and will return immediately, you can also pass a call back to commitAsync which will get called with commit results.
Like Producer the properties for the consumer are::
bootstrap.servers=localhost:9092
key.deserializer=org.apache.kafka.common.serialization.LongDeserializer
value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
group.id=kafka-consumer-1bootstrap.servers is same as producer. Consumer requires deserialization and properties key.deserializer, value.deserializer provides that information. You need to provide your own implementation in case if you sending your own message type. Other configurations are also there like SSL which you can read on Kafka Documentation site. As our examples are pretty simple we are not dealing with other configuration options.
Serialization And Deserialization
If you have a custom message schema and if you want to send it to a Topic in Kafka you will need to implement org.apache.kafka.common.serialization.Serializer and org.apache.kafka.common.serialization.Deserializer. There are various Serializer available in the market like Jackson (for JSON), XStream (for XML), Smile, Kryo (a fast, compact binary serialization format) or you can use Java Object Serialization. For this example, I am using Kryo.
package com.kafka.sample;
import java.util.Date;
import java.util.Map;
import org.apache.kafka.common.serialization.Deserializer;
import org.apache.kafka.common.serialization.Serializer;
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.ByteBufferInput;
import com.esotericsoftware.kryo.io.ByteBufferOutput;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
public class KryoSerialization implements Serializer<Employee>,Deserializer<Employee> {
private ThreadLocal<Kryo> kryos = new ThreadLocal<Kryo>() {
protected Kryo initialValue() {
Kryo kryo = new Kryo();
kryo.addDefaultSerializer(Employee.class, new KryoSerializer());
return kryo;
};
};
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
}
@Override
public Employee deserialize(String topic, byte[] data) {
Employee employee = kryos.get().readObject(new ByteBufferInput(data), Employee.class);
return employee;
}
@Override
public byte[] serialize(String topic, Employee data) {
ByteBufferOutput output = new ByteBufferOutput(100);
kryos.get().writeObject(output, data);
return output.toBytes();
}
@Override
public void close() {
kryos.remove();
}
private static class KryoSerializer extends com.esotericsoftware.kryo.Serializer<Employee> {
@Override
public Employee read(Kryo kryo, Input input, Class<Employee> clazz) {
Employee emp = new Employee();
emp.setEmpId(input.readLong());
emp.setFirstName(input.readString());
emp.setLastName(input.readString());
emp.setJoiningDate(new Date(input.readLong(true)));
return emp;
}
@Override
public void write(Kryo kryo, Output output, Employee message) {
output.writeLong(message.getEmpId());
output.writeString(message.getFirstName());
output.writeString(message.getLastName());
output.writeLong(message.getJoiningDate().getTime(), true);
}
}
}Serializer and Deserializer have two methods serialize and deserialize and what we are doing in this two method is handing over the task to Kryo. The write and read sequence of data in KryoSerializer will be same as you can see in the read and write method. We'll require changing our properties file to use this new serializer in producer and consumer.
Thus we have seen the basics of Apache Kafka, its use cases, installation and working with Apache Kafka API's in Java. Many projects like real time based and streaming based uses Apache Kafka and I hope this post helps you get started with Apache Kafka. If you want to experiment with the examples you can find the source here.